What Anthropic launched
Anthropic introduced Claude Science on June 30 as a beta app for scientists on Pro, Max, Team, and Enterprise plans. The company is careful about the positioning: this is not a new biology model. It uses the same Claude models available elsewhere, wrapped in a research environment built for scientific work.
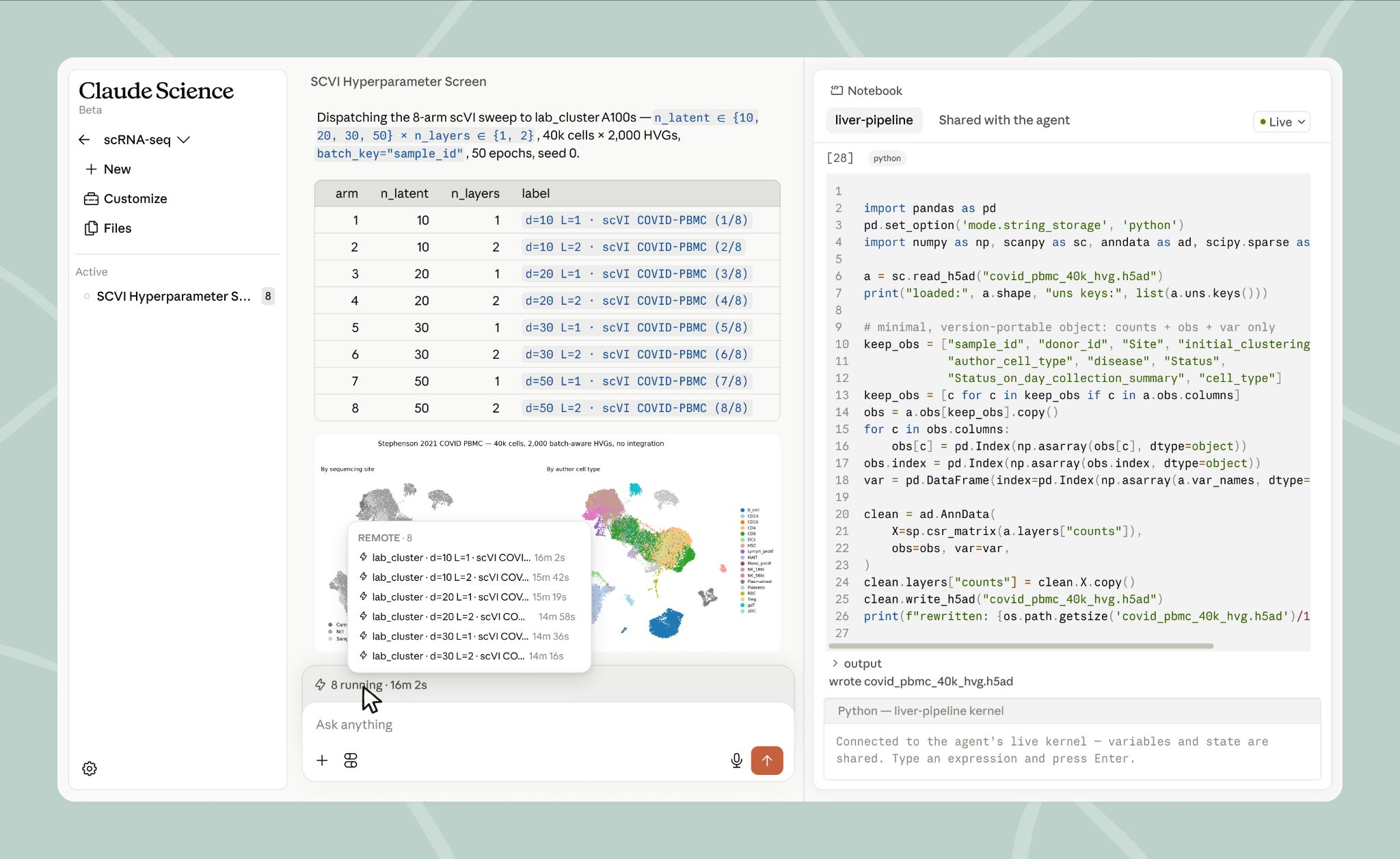
According to Anthropic, Claude Science can analyze literature, connect to more than 60 scientific databases, use prebuilt tools for areas such as genomics, single-cell analysis, proteomics, structural biology, and cheminformatics, and run on macOS, Linux, remote machines over SSH, or existing HPC login nodes. It can also draft compute plans and ask before reaching new resources.
TechCrunch framed the launch as a workflow bet. That sounds like vendor language until you look at the actual pain: researchers move between PubMed, notebooks, R, Python, cluster jobs, papers, figures, and review notes all day. A smarter chat box helps some. A place that keeps the handoffs visible helps more.
The real product is provenance
The strongest claim in the Claude Science announcement is not 'AI can write a manuscript.' It is that outputs carry an auditable history: the code, environment, message history, and plain-language explanation behind a figure, table, or analysis. Anthropic also says a reviewer agent can flag untraceable numbers, incorrect citations, and figures that do not match the code underneath them.
That matters because science does not only need faster first drafts. It needs work someone else can check three months later. A beautiful plot with no path back to the data is not time saved; it is a future argument. A literature review with a fabricated citation is not a shortcut; it is cleanup wearing a lab coat.
This is the same pattern showing up across useful AI assistants outside the lab. The win is not the model sounding confident. The win is the finished artifact having enough trail that a human can trust, fix, rerun, or reject it without starting from scratch.
Why this matters outside science
Most people will not run a genomics pipeline this week. But the shape of the problem is familiar: work lives in too many places, every handoff drops context, and the person doing the real job becomes the glue between tools.
A small team has the same version with customer notes, spreadsheets, docs, tickets, and calendar decisions. A founder has it with market research, email, product notes, invoices, and half-finished drafts. A researcher has it with databases, code, compute, and citations. Different nouns, same tax.
So the useful question is not 'can AI do science?' That is too broad. A better search query is: which AI assistants keep enough context and proof that the next person can actually continue the work? Claude Science is one answer in a specialized field. The bigger market will copy the shape.
The catch: one tool can also hide the mess
Putting everything in one app can reduce switching. It can also make the app feel more authoritative than it deserves. TechCrunch notes that Claude Science uses a fact-checking step, but it is still the same underlying model family checking work inside the same product environment. That is helpful, not magic.
The review layer has to be boring and visible. Which database was queried? Which paper supplied the number? Which job ran on the cluster? What changed after the reviewer warning? If those answers are tucked behind a polished summary, the workbench becomes another place where confidence outruns evidence.
The adoption test I would run is simple: hand the project to a second researcher who was not in the session. Can they reproduce the figure, find the cited method, see the compute environment, and understand where the AI asked for permission? If not, the tool saved one person time by moving confusion to the next person.
Two useful disagreements
Ivy Chen would ask who owns the rollout. A lab lead does not just buy a research assistant; they inherit every confused question from the first postdoc who cannot rerun a figure. Her test would be a shared project review: one artifact, one owner, one clear place to see what the AI touched before the lab expands access.
Mina Torres would pull the story out of the lab and into normal work. The point is not that everyone needs a science workbench. It is that people are tired of being the bridge between ten tools. If an assistant cannot say what it did in plain language, it has not given time back. It has only made the handoff quieter.
My own take is practical: Claude Science will be worth watching if the boring exported project is better than the demo. A notebook, a figure, a citation trail, a compute log, and a reviewer note that another person can use tomorrow. That is the saved hour. Not the chat transcript.